
Cost optimization with GCP
It’s all money!
It’s all money!

Building highways over a series of internet tubes - but with potatoes
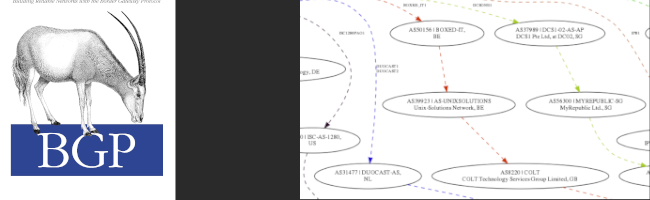
There is no place like local-router-id

This is my spot and I’m not leaving it!
Now, this is podracing.

The power of Linux!

Using node_exporter to monitor pfsense

A better way to manage on-call alerts.
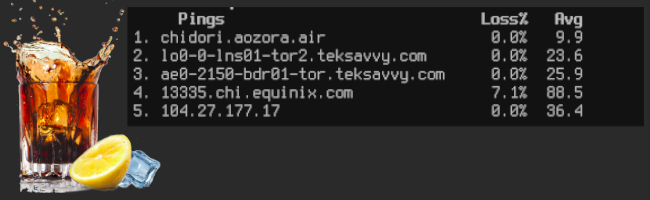
ICMP my drink

Many snakes!

Upgraaaaaaade!

Remote power!
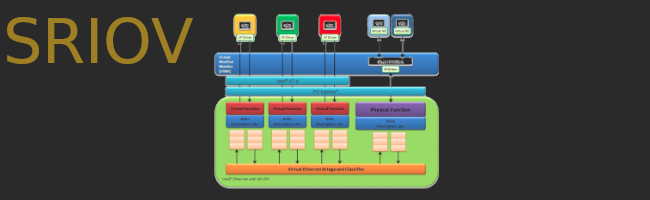
SRIOV boogaloo

Unlimited Pooooowweeeer!

Ping ping ping - it’s down!

Musing and tidbits from the LAN ETS events.

Large scale automated disasters ;)

Ping ping ping - it’s down!

Docker command causing a stack-trace

Erratic scrolling behavior in Ubuntu 18.04 and Visual Studio Code

How to register to an IRC server!

Deploying a Stratum 1 NTP server with a Raspberry Pi and a GPS as a timing source.

Mint 19 as a daily OS for an HP Laptop

Automating Hugo blog deployment using Github Actions!