Transcribing 30 Hours of Audio with OpenAI for LLM RAG
Ask a friendly robot the meaning of CY150 - Investigation of online crimes (summer edition)
Context
What
- Using a transcription service to transform to text 30 hours of audio classes.
- Using $INSERT_LLM_HERE to query the data through a text chat, basic RAG use-case.
- Try to reduce costs where possible.
Why
- I’ve been taking remote Computer Science university classes.
- Each session (2x a week, 3~ hours) are done through Zoom and is recorded.
How
Initial experimentation
Getting the zoom recordings
- Zoom recordings are not downloadable by default –> Zoom support KB
- You can use a handy dandy Chrome extension –> Zoom recorder Chrome store link
- For some reason, the audio only download did not work.
- I had to download the video + audio file, which was not ideal as it’s bigger and I do not need the video.
A note on the Zoom downloader extension : - Honestly, Chrome extensions are a bit scary. - I’ve had a look at the Zoom extension, using Chrome extension viewer - Yes, use another extension to have a look at an extension - endless loop! - Nothing jumped out as particularly dangerous - There is some Firebase analytics components, it looks like the author is gathering stats on usage.
At this point, I had all the classes, but still in video format. For ease of portability and making the file size smaller, extracting the audio is appropriate.
Extracting the audio from an MP4 file
The magic of ffmpeg What is ffpmeg :)
ffmpeg -i GMT20240508-224705_Recording_1920x1200.mp4 -acodec libmp3lame -metadata TITLE="audio-class-2" audio-class-2.mp3
I realized after that this re-encodes the audio, you can also extract directly.
#Find the audio stream track
fprobe cours9.mp4
#Extract
ffmpeg -i cours9.mp4 -map 0:a -acodec copy audio-potato.mp4
AWS Transcribe
- First experiment was with AWS Transcribe (https://aws.amazon.com/transcribe/)
- Requires zero infrastructure
- Upload the audio file to S3
- Start the transcription job
- Supports french out of the box with AWS models
- Expensive!
- A 3 hours transcription = 3.50$
- I had 30 hours = 30.50$ + Tax
Using Whisper OpenAI locally
- The OpenAI folks we’re kind enough to publish their Whisper tool. Github link
- It takes in an audio file and transcribes it.
- It can use your GPU to be faster.
- It’s free!
Starting a translation
#Create your Python venv
python -m venv
source venv/bin/activate
pip install -U openai-whisper
#Start the transcription
whisper --language French potato.mp3 --output_format all --model large --task transcribe
This was enough to transcribe 30 hours of audio in about 2 hours, which was fast enough for my needs.
Couple of things I discovered : - The model can still “hallucinate”, but mostly when no audio is detected - It really expects 30 second of continuous audio - Large gaps in the audio can impact the context sliding window and you will lose full sentences. - I had to use Audacity to remove any long silences. - WER and CER scores we’re pretty good, but it has problems with acronyms and context specific words.
Example of an hallucination –> Link to the Github discussion of the issue
1
00:00:00,000 --> 00:00:03,000
Sous-titres réalisés par la communauté d'Amara.org
2
00:00:30,000 --> 00:00:33,000
Sous-titres réalisés par la communauté d'Amara.org
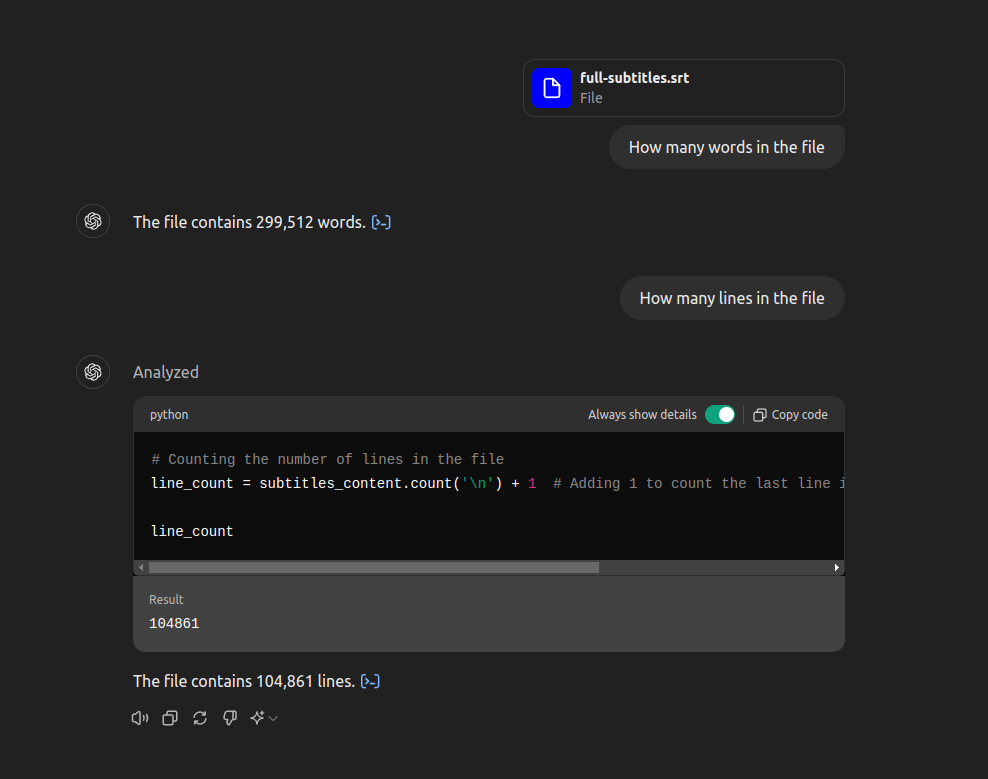
Once you have a big file of the entire 30 hours transcribed, it’s time to feed this to OpenAI.
I was using the paid version with the 4o mode. You can simply upload your text file, they take care of the magic!
Trusting the LLM linkage of your data is the most challenging part of all of this :
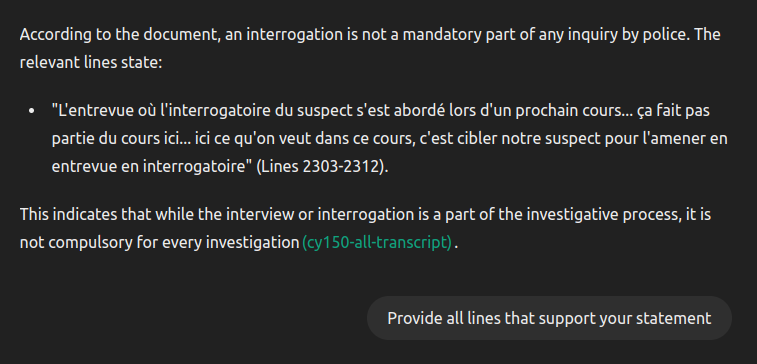
- According to Canadian law, a police interview is not a obligatory step of an investigation
- Asking the question to the model does provide a correct answer.
- That said, if you ask the mode to indicate which part of the document supports that statement, it provides a section that is someewhat unrelated.
- The actual french translation is closer to “We are not discussing the police interview as part of this class, it’s the next one”
- So, not an actual answer or supporting material related to our question
Overall, it was a nice experiment and it’s a good way to parse large data sets.
That said, the nature of the LLM interpretation means that I would be weary of trusting blankly all the replies.